
SageMaker HyperPod の Deep health checks を試してみる
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは!クラウド事業本部コンサルティング部のたかくに(@takakuni_)です。
EKS オーケストレータの SageMaker HyperPod には Deep health checks というものがあります。
一言で言うと、インスタンスグループで利用可能になる前にインスタンスのハードウェアやコンポーネントのパフォーマンス評価を行うヘルスチェックです。
今回はこの Deep health checks を試してみたいと思います。
Deep health checks の監視項目
Deep health checks の監視項目は以下になります。インスタンスレベルとクラスターレベルの 2 種類があり、インスタンスタイプ別(Trainium か GPU)にテストケースが異なります。
長時間実行し続けるワークロードにおいて、事前にハードウェアレベルまでテストできるのは素晴らしいですね。
インスタンスレベル
| カテゴリ | ユーティリティ名 | 互換インスタンスタイプ | 説明 |
|---|---|---|---|
| アクセラレータ | GPU/NVLink カウント | GPU | GPU/NVLink の数を検証 |
| アクセラレータ | DCGM レベル 4 診断 | GPU | DCGM(NVIDIA Data Center GPU Manager)を使用してレベル 4 の診断を実行し、追加のメモリテストを含む NVIDIA GPU の健全性と機能を評価 |
| アクセラレータ | Neuron sysfs | Trainium | Trainium を搭載したインスタンスで、Neuron ドライバーから直接伝播される Neuron sysfs からカウンターを読み取り Neuron デバイスの健全性を判断 |
| アクセラレータ | Neuron ハードウェアチェック | Trainium | 数値を生成するトレーニングワークロードを実行し、ハードウェアをテストす |
| アクセラレータ | NCCOM ローカルテスト | Trainium | 単一の Trainium ノードでの集合通信操作の性能を評価 |
| ネットワーク | EFA | GPU および Trainium | 接続された EFA デバイスのレイテンシーと帯域幅のベンチマークを実行 |
クラスターレベル
| カテゴリ | ユーティリティ名 | 互換インスタンスタイプ | 説明 |
|---|---|---|---|
| アクセラレータ | NCCL テスト | GPU | 複数の NVIDIA GPU での集合通信操作の性能を検証 |
| アクセラレータ | NCCOM クラスターテスト | Trainium | 複数の Trainium ノードでの集合通信操作の性能を検証 |
やってみる
それでは実際に Deep health checks をやってみようと思います。各インスタンスグループで OnStartDeepHealthChecks を定義しヘルスチェックの有無を指定します。
OnStartDeepHealthChecks
A flag indicating whether deep health checks should be performed when the cluster instance group is created or updated.Type: Array of strings
Array Members: Minimum number of 1 item. Maximum number of 2 items.
Valid Values: InstanceStress | InstanceConnectivity
Required: No
テストケースの通り、サポートしているのは GPU インスタンスタイプ(P、G、Trn 系)を指定したインスタンスグループになります。ドキュメントにも記載されていますね。
The HyperPod deep health check and health monitoring agent supports GPU and Trn instances.
クラスターの作成
今回は次のパラメーターで HyperPod クラスターを作成します。worker-group-1 で ml.g5.12xlarge を指定し、OnStartDeepHealthChecks にストレスチェックとネットワークのチェックを含めています。
{
"ClusterName": "ml-cluster",
"Orchestrator": {
"Eks": {
"ClusterArn": "arn:aws:eks:us-west-2:123456789012:cluster/hyperpod-eks-cluster"
}
},
"InstanceGroups": [
{
"InstanceGroupName": "worker-group-1",
+ "InstanceType": "ml.g5.12xlarge",
"InstanceCount": 2,
"InstanceStorageConfigs": [
{
"EbsVolumeConfig": {
"VolumeSizeInGB": 500
}
}
],
"LifeCycleConfig": {
"SourceS3Uri": "s3://hyperpod-eks-bucket-123456789012-us-west-2",
"OnCreate": "on_create.sh"
},
"ExecutionRole": "arn:aws:iam::123456789012:role/hyperpod-eks-ExecutionRole-us-west-2",
"ThreadsPerCore": 2,
+ "OnStartDeepHealthChecks": ["InstanceStress", "InstanceConnectivity"]
}
],
"VpcConfig": {
"SecurityGroupIds": ["sg-0a0ab81a7745a00da"],
"Subnets": ["subnet-091a8cf419deb16e8"]
},
"NodeRecovery": "Automatic"
}
AWS CLI でクラスターを作成します。
aws sagemaker create-cluster \
--cli-input-json file://cluster-config.json \
--region $AWS_REGION
インスタンスグループ
インスタンスグループの中身を見てみます。クラスターのステータスは Inservice ですが、インスタンスは DeepHealthCheckInProgress に遷移していますね。
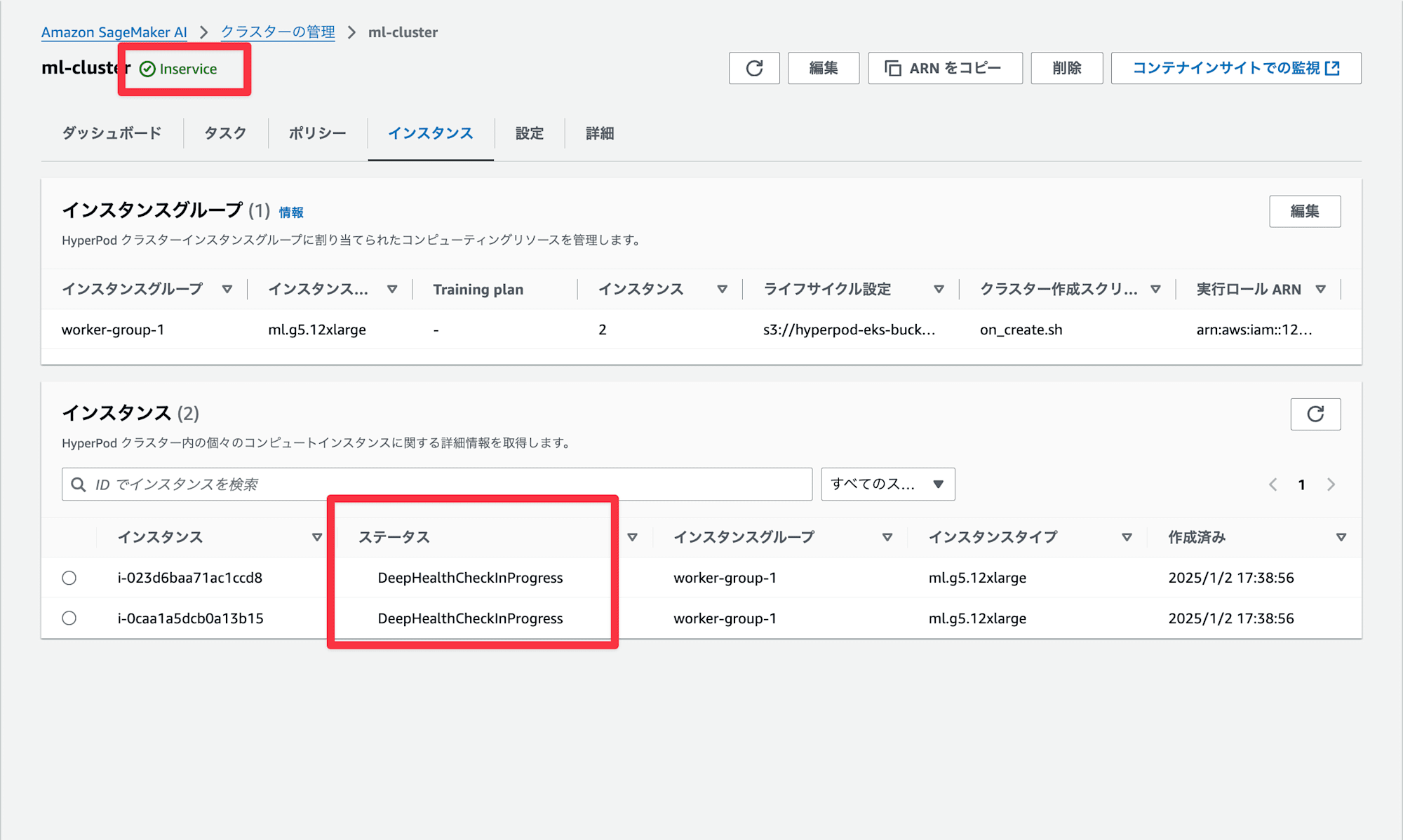
約 40 分程度経過したのちにインスタンスは Running に遷移しました。
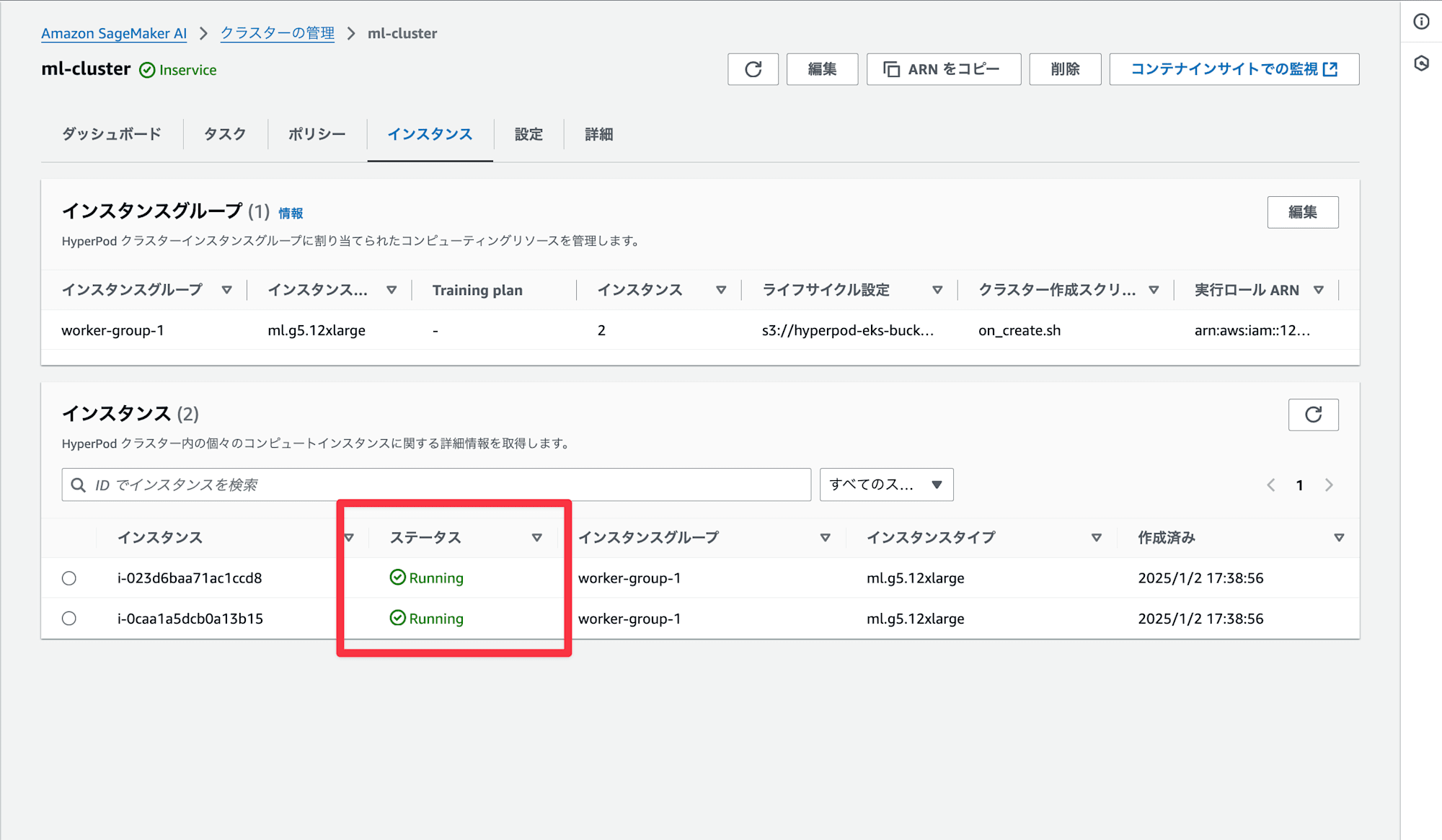
ログを見てみる
クラスターレベル
ログを見てみましょう。クラスターレベルのログは CloudWatch Logs に DeepHealthCheckResults/<log_stream_id> のストリーム名で保管されます。
タイムスタンプから、ライフサイクルスクリプトが実行されたのちに、ディープヘルスチェックが起動しています。
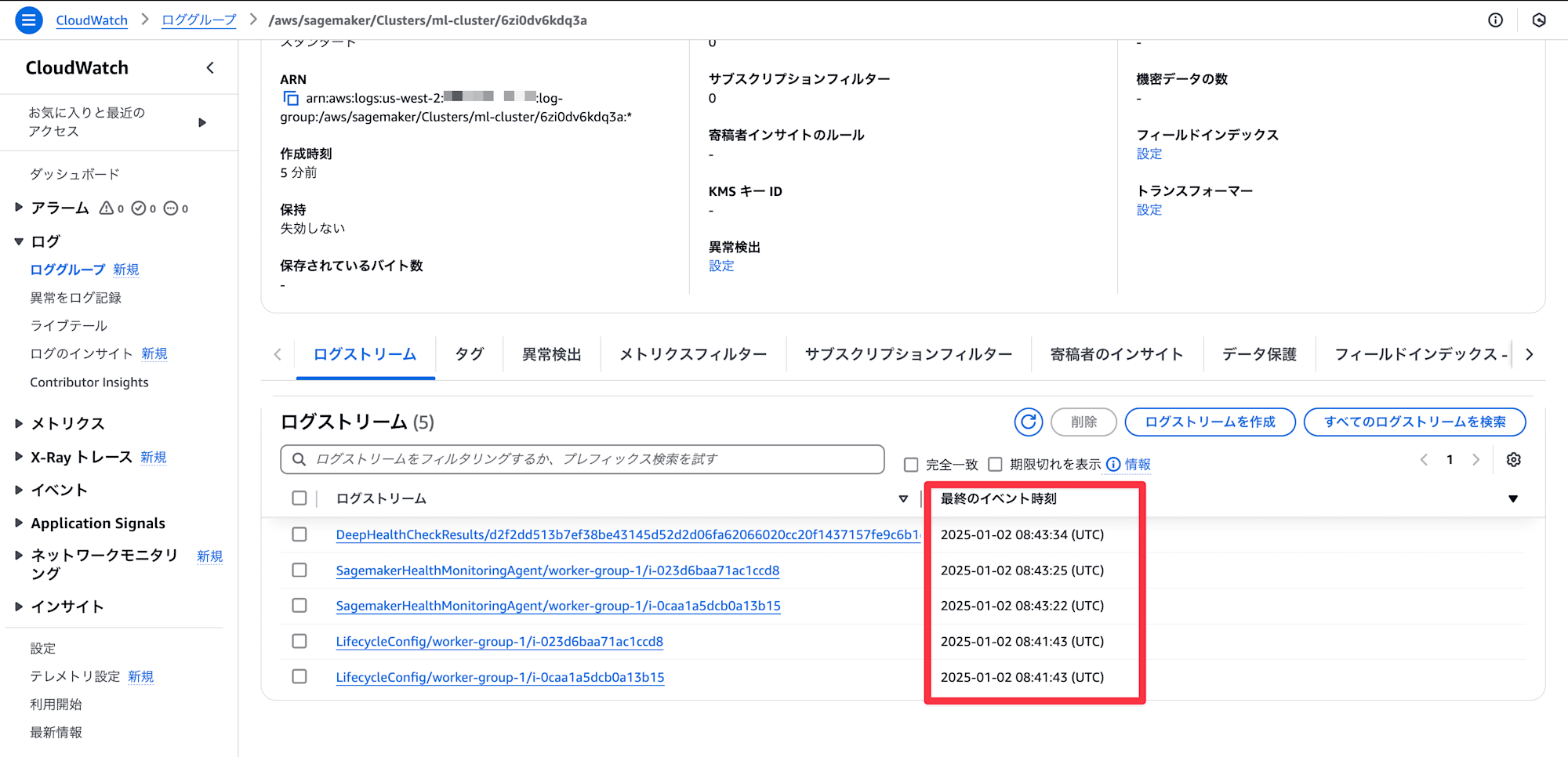
ちなみに SagemakerHealthMonitoringAgent/ から始まるものは SageMaker HyperPod health-monitoring agent のログのようです。
今回は G 系(GPU)を利用したため、GPU/NVLink count, DCGM, EFA, NCCL がテストケースとして利用されています。
2025-01-02T08:43:34.310Z Deep health check configuration validation passed
2025-01-02T08:46:39.966Z 2 out of 2 nodes succeeded HARDWARE_CHECK test. Instance IDs: [i-023d6baa71ac1ccd8 i-0caa1a5dcb0a13b15]
2025-01-02T09:16:53.003Z 2 out of 2 nodes succeeded DCGM test. Instance IDs: [i-023d6baa71ac1ccd8 i-0caa1a5dcb0a13b15]
2025-01-02T09:17:56.884Z 2 out of 2 nodes succeeded EFA test. Instance IDs: [i-023d6baa71ac1ccd8 i-0caa1a5dcb0a13b15]
2025-01-02T09:20:03.692Z 0 nodes failed NCCL test at batch size 2. Instance IDs: []
2025-01-02T09:20:05.252Z 2 out of 2 nodes succeeded NCCL test. Instance IDs: [i-023d6baa71ac1ccd8 i-0caa1a5dcb0a13b15]
インスタンスレベル
インスタンスにログインしログを確認してみます。まずは SSM でノードにログインします。
# SSM で worker-group-1 のノードにログイン
curl -O https://raw.githubusercontent.com/aws-samples/awsome-distributed-training/main/1.architectures/5.sagemaker-hyperpod/easy-ssh.sh
chmod +x easy-ssh.sh
./easy-ssh.sh -c worker-group-1 ml-cluster
worker-group-1 の i-023d6baa71ac1ccd8 にログインできました。
Exiting session with sessionId: cm-takakuni-lvcdajcll9xaracha5oqveqbcq.
[cloudshell-user@ip-10-140-1-80 ~]$ ./easy-ssh.sh -c worker-group-1 ml-cluster
=================================================
==== 🚀 HyperPod Cluster Easy SSH Script! 🚀 ====
=================================================
Cluster id: 6zi0dv6kdq3a
Instance id: i-023d6baa71ac1ccd8
Node Group: worker-group-1
1. Detected ml-cluster in ~/.ssh/config. Skipping adding...
cat: /home/cloudshell-user/.ssh/id_rsa.pub: No such file or directory
2. Detected SSH public key ~/.ssh/id_rsa.pub on the cluster. Skipping adding...
Now you can run:
$ ssh ml-cluster
Starting session with SessionId: cm-takakuni-jhqv5u62kjtk4rt47nzof25dhe
sh-4.2#
ログは /var/log/aws/clusters/sagemaker-deep-health-check.log に保管されています。cat で確認します。
# ノードにログイン後 cat でログを確認
cat /var/log/aws/clusters/sagemaker-deep-health-check.log
ログが保管されていますね。(長い...)
sh-4.2# cat /var/log/aws/clusters/sagemaker-deep-health-check.log
{"level":"info","ts":"2025-01-02T08:45:18Z","msg":"Instance type: ml.g5.12xlarge, region: us-west-2"}
{"level":"info","ts":"2025-01-02T08:45:18Z","msg":"Test to be executed: hardware_check"}
{"level":"info","ts":"2025-01-02T08:45:18Z","msg":"Executing hardware stress"}
{"level":"info","ts":"2025-01-02T08:45:18Z","msg":"Executing Hardware stress check with command: stress-ng, and args: [--cpu 48 --vm 2 --hdd 1 --fork 8 --switch 4 --timeout 60 --metrics]"}
{"level":"info","ts":"2025-01-02T08:46:18Z","msg":"stress-ng success"}
{"level":"info","ts":"2025-01-02T08:46:18Z","msg":"executing Nvidia GPU and PCI count check"}
{"level":"info","ts":"2025-01-02T08:46:18Z","msg":"Running GPU and PCI verification check"}
{"level":"info","ts":"2025-01-02T08:46:18Z","msg":"Executing lspci to get list of pcis. Command: lspci -d10de: -n | grep 2237 | wc -l"}
{"level":"info","ts":"2025-01-02T08:46:18Z","msg":"Executing nvidia-smi to get list of GPUs. Command: nvidia-smi --list-gpus | wc -l"}
{"level":"info","ts":"2025-01-02T08:46:18Z","msg":"GpuPci Count check success"}
{"level":"error","ts":"2025-01-02T08:46:23Z","msg":"error publishing metric to cloudwatch: operation error CloudWatch: PutMetricData, get identity: get credentials: failed to refresh cached credentials, no EC2 IMDS role found, operation error ec2imds: GetMetadata, request canceled, context deadline exceeded"}
{"level":"info","ts":"2025-01-02T08:46:23Z","msg":"Logging Burnin Execution time metric","ExecutionTime":1,"_aws":{"Timestamp":1735807583304,"CloudWatchMetrics":[{"Namespace":"SagemakerBurninTest","Dimensions":[[]],"Metrics":[{"Name":"ExecutionTime","Unit":"Count"}]}]}}
{"level":"info","ts":"2025-01-02T08:46:23Z","msg":"Logging BurninExecutionCount metric","Burnin":"hardware_check_nvidia","ExecutionCount":1,"_aws":{"Timestamp":1735807583304,"CloudWatchMetrics":[{"Namespace":"SagemakerBurninTest","Dimensions":[["Burnin"]],"Metrics":[{"Name":"ExecutionCount","Unit":"Count"}]}]}}
{"level":"error","ts":"2025-01-02T08:46:26Z","msg":"error publishing metric to cloudwatch: operation error CloudWatch: PutMetricData, get identity: get credentials: failed to refresh cached credentials, no EC2 IMDS role found, operation error ec2imds: GetMetadata, exceeded maximum number of attempts, 3, request send failed, Get \"http://169.254.169.254/latest/meta-data/iam/security-credentials/\": dial tcp 169.254.169.254:80: i/o timeout"}
{"level":"info","ts":"2025-01-02T08:46:26Z","msg":"Logging Burnin Execution time metric","ExecutionTime":1,"_aws":{"Timestamp":1735807586056,"CloudWatchMetrics":[{"Namespace":"SagemakerBurninTest","Dimensions":[[]],"Metrics":[{"Name":"ExecutionTime","Unit":"Count"}]}]}}
{"level":"info","ts":"2025-01-02T08:46:26Z","msg":"Logging Burnin Execution time metric","Burnin":"hardware_check_nvidia","ExecutionTime":60.289799651,"_aws":{"Timestamp":1735807586057,"CloudWatchMetrics":[{"Namespace":"SagemakerBurninTest","Dimensions":[["Burnin"]],"Metrics":[{"Name":"ExecutionTime","Unit":"Seconds"}]}]}}
{"level":"info","ts":"2025-01-02T08:46:43Z","msg":"Instance type: ml.g5.12xlarge, region: us-west-2"}
{"level":"info","ts":"2025-01-02T08:46:43Z","msg":"Test to be executed: dcgm"}
{"level":"info","ts":"2025-01-02T08:46:43Z","msg":"Executing dcgm"}
{"level":"info","ts":"2025-01-02T08:46:43Z","msg":"Running dcgmi test with commands: [diag --run 4 -p diagnostic.gflops_tolerance_pcnt=0.3\\;memtest.test7=true\\;memtest.test0=true\\;memtest.test2=true\\;memtest.test10=true\\;memtest.test9=true\\;memtest.test_duration=90\\;memtest.test3=true\\;memtest.test1=true\\;memtest.test6=true\\;memtest.test4=true\\;memtest.test5=true\\;memtest.test8=true --json --fail-early]"}
{"level":"info","ts":"2025-01-02T09:15:53Z","msg":"dcgm diagnostic raw output:\n {\n\t\"DCGM GPU Diagnostic\" : \n\t{\n\t\t\"test_categories\" : \n\t\t[\n\t\t\t{\n\t\t\t\t\"category\" : \"Deployment\",\n\t\t\t\t\"tests\" : \n\t\t\t\t[\n\t\t\t\t\t{\n\t\t\t\t\t\t\"name\" : \"Denylist\",\n\t\t\t\t\t\t\"results\" : \n\t\t\t\t\t\t[\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"status\" : \"Pass\"\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t]\n\t\t\t\t\t},\n\t\t\t\t\t{\n\t\t\t\t\t\t\"name\" : \"NVML Library\",\n\t\t\t\t\t\t\"results\" : \n\t\t\t\t\t\t[\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"status\" : \"Pass\"\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t]\n\t\t\t\t\t},\n\t\t\t\t\t{\n\t\t\t\t\t\t\"name\" : \"CUDA Main Library\",\n\t\t\t\t\t\t\"results\" : \n\t\t\t\t\t\t[\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"status\" : \"Pass\"\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t]\n\t\t\t\t\t},\n\t\t\t\t\t{\n\t\t\t\t\t\t\"name\" : \"Permissions and OS Blocks\",\n\t\t\t\t\t\t\"results\" : \n\t\t\t\t\t\t[\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"status\" : \"Pass\"\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t]\n\t\t\t\t\t},\n\t\t\t\t\t{\n\t\t\t\t\t\t\"name\" : \"Persistence Mode\",\n\t\t\t\t\t\t\"results\" : \n\t\t\t\t\t\t[\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"status\" : \"Pass\"\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t]\n\t\t\t\t\t},\n\t\t\t\t\t{\n\t\t\t\t\t\t\"name\" : \"Environment Variables\",\n\t\t\t\t\t\t\"results\" : \n\t\t\t\t\t\t[\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"status\" : \"Pass\"\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t]\n\t\t\t\t\t},\n\t\t\t\t\t{\n\t\t\t\t\t\t\"name\" : \"Page Retirement/Row Remap\",\n\t\t\t\t\t\t\"results\" : \n\t\t\t\t\t\t[\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"status\" : \"Pass\"\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t]\n\t\t\t\t\t},\n\t\t\t\t\t{\n\t\t\t\t\t\t\"name\" : \"Graphics Processes\",\n\t\t\t\t\t\t\"results\" : \n\t\t\t\t\t\t[\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"status\" : \"Pass\"\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t]\n\t\t\t\t\t},\n\t\t\t\t\t{\n\t\t\t\t\t\t\"name\" : \"Inforom\",\n\t\t\t\t\t\t\"results\" : \n\t\t\t\t\t\t[\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"status\" : \"Pass\"\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t]\n\t\t\t\t\t}\n\t\t\t\t]\n\t\t\t},\n\t\t\t{\n\t\t\t\t\"category\" : \"Integration\",\n\t\t\t\t\"tests\" : \n\t\t\t\t[\n\t\t\t\t\t{\n\t\t\t\t\t\t\"name\" : \"PCIe\",\n\t\t\t\t\t\t\"results\" : \n\t\t\t\t\t\t[\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"gpu_id\" : \"0\",\n\t\t\t\t\t\t\t\t\"info\" : \"GPU 0 GPU to Host bandwidth:\\t\\t13.21 GB/s, GPU 0 Host to GPU bandwidth:\\t\\t13.46 GB/s, GPU 0 bidirectional bandwidth:\\t22.67 GB/s, GPU 0 GPU to Host latency:\\t\\t2.108 us, GPU 0 Host to GPU latency:\\t\\t2.168 us, GPU 0 bidirectional latency:\\t\\t4.841 us\",\n\t\t\t\t\t\t\t\t\"status\" : \"Pass\"\n\t\t\t\t\t\t\t},\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"gpu_id\" : \"1\",\n\t\t\t\t\t\t\t\t\"info\" : \"GPU 1 GPU to Host bandwidth:\\t\\t13.21 GB/s, GPU 1 Host to GPU bandwidth:\\t\\t13.46 GB/s, GPU 1 bidirectional bandwidth:\\t22.67 GB/s, GPU 1 GPU to Host latency:\\t\\t2.461 us, GPU 1 Host to GPU latency:\\t\\t2.475 us, GPU 1 bidirectional latency:\\t\\t4.802 us\",\n\t\t\t\t\t\t\t\t\"status\" : \"Pass\"\n\t\t\t\t\t\t\t},\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"gpu_id\" : \"2\",\n\t\t\t\t\t\t\t\t\"info\" : \"GPU 2 GPU to Host bandwidth:\\t\\t13.21 GB/s, GPU 2 Host to GPU bandwidth:\\t\\t13.46 GB/s, GPU 2 bidirectional bandwidth:\\t22.67 GB/s, GPU 2 GPU to Host latency:\\t\\t2.422 us, GPU 2 Host to GPU latency:\\t\\t2.411 us, GPU 2 bidirectional latency:\\t\\t4.780 us\",\n\t\t\t\t\t\t\t\t\"status\" : \"Pass\"\n\t\t\t\t\t\t\t},\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"gpu_id\" : \"3\",\n\t\t\t\t\t\t\t\t\"info\" : \"GPU 3 GPU to Host bandwidth:\\t\\t13.21 GB/s, GPU 3 Host to GPU bandwidth:\\t\\t13.46 GB/s, GPU 3 bidirectional bandwidth:\\t22.67 GB/s, GPU 3 GPU to Host latency:\\t\\t2.351 us, GPU 3 Host to GPU latency:\\t\\t2.344 us, GPU 3 bidirectional latency:\\t\\t4.573 us\",\n\t\t\t\t\t\t\t\t\"status\" : \"Pass\"\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t]\n\t\t\t\t\t}\n\t\t\t\t]\n\t\t\t},\n\t\t\t{\n\t\t\t\t\"category\" : \"Hardware\",\n\t\t\t\t\"tests\" : \n\t\t\t\t[\n\t\t\t\t\t{\n\t\t\t\t\t\t\"name\" : \"GPU Memory\",\n\t\t\t\t\t\t\"results\" : \n\t\t\t\t\t\t[\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"gpu_id\" : \"0\",\n\t\t\t\t\t\t\t\t\"info\" : \"GPU 0 Allocated 23091733368 bytes (97.9%)\",\n\t\t\t\t\t\t\t\t\"status\" : \"Pass\"\n\t\t\t\t\t\t\t},\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"gpu_id\" : \"1\",\n\t\t\t\t\t\t\t\t\"info\" : \"GPU 1 Allocated 23091733368 bytes (97.9%)\",\n\t\t\t\t\t\t\t\t\"status\" : \"Pass\"\n\t\t\t\t\t\t\t},\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"gpu_id\" : \"2\",\n\t\t\t\t\t\t\t\t\"info\" : \"GPU 2 Allocated 23091733368 bytes (97.9%)\",\n\t\t\t\t\t\t\t\t\"status\" : \"Pass\"\n\t\t\t\t\t\t\t},\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"gpu_id\" : \"3\",\n\t\t\t\t\t\t\t\t\"info\" : \"GPU 3 Allocated 23091733368 bytes (97.9%)\",\n\t\t\t\t\t\t\t\t\"status\" : \"Pass\"\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t]\n\t\t\t\t\t},\n\t\t\t\t\t{\n\t\t\t\t\t\t\"name\" : \"Diagnostic\",\n\t\t\t\t\t\t\"results\" : \n\t\t\t\t\t\t[\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"gpu_id\" : \"0\",\n\t\t\t\t\t\t\t\t\"info\" : \"GPU 0 Allocated space for 35 output matricies from 20994372403 bytes available., GPU 0 Running with precisions: FP64 0, FP32 1, FP16 1, GPU 0 GPU 0 calculated at approximately 759.48 gigaflops during this test\",\n\t\t\t\t\t\t\t\t\"status\" : \"Pass\"\n\t\t\t\t\t\t\t},\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"gpu_id\" : \"1\",\n\t\t\t\t\t\t\t\t\"info\" : \"GPU 1 Allocated space for 35 output matricies from 20994372403 bytes available., GPU 1 Running with precisions: FP64 0, FP32 1, FP16 1, GPU 1 GPU 1 calculated at approximately 765.71 gigaflops during this test\",\n\t\t\t\t\t\t\t\t\"status\" : \"Pass\"\n\t\t\t\t\t\t\t},\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"gpu_id\" : \"2\",\n\t\t\t\t\t\t\t\t\"info\" : \"GPU 2 Allocated space for 35 output matricies from 20994372403 bytes available., GPU 2 Running with precisions: FP64 0, FP32 1, FP16 1, GPU 2 GPU 2 calculated at approximately 759.48 gigaflops during this test\",\n\t\t\t\t\t\t\t\t\"status\" : \"Pass\"\n\t\t\t\t\t\t\t},\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"gpu_id\" : \"3\",\n\t\t\t\t\t\t\t\t\"info\" : \"GPU 3 Allocated space for 35 output matricies from 20994372403 bytes available., GPU 3 Running with precisions: FP64 0, FP32 1, FP16 1, GPU 3 GPU 3 calculated at approximately 759.48 gigaflops during this test\",\n\t\t\t\t\t\t\t\t\"status\" : \"Pass\"\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t]\n\t\t\t\t\t},\n\t\t\t\t\t{\n\t\t\t\t\t\t\"name\" : \"Pulse Test\",\n\t\t\t\t\t\t\"results\" : \n\t\t\t\t\t\t[\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"gpu_id\" : \"0\",\n\t\t\t\t\t\t\t\t\"status\" : \"Skip\"\n\t\t\t\t\t\t\t},\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"gpu_id\" : \"1\",\n\t\t\t\t\t\t\t\t\"status\" : \"Skip\"\n\t\t\t\t\t\t\t},\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"gpu_id\" : \"2\",\n\t\t\t\t\t\t\t\t\"status\" : \"Skip\"\n\t\t\t\t\t\t\t},\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"gpu_id\" : \"3\",\n\t\t\t\t\t\t\t\t\"status\" : \"Skip\"\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t]\n\t\t\t\t\t}\n\t\t\t\t]\n\t\t\t},\n\t\t\t{\n\t\t\t\t\"category\" : \"Stress\",\n\t\t\t\t\"tests\" : \n\t\t\t\t[\n\t\t\t\t\t{\n\t\t\t\t\t\t\"name\" : \"Targeted Stress\",\n\t\t\t\t\t\t\"results\" : \n\t\t\t\t\t\t[\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"gpu_id\" : \"0\",\n\t\t\t\t\t\t\t\t\"info\" : \"GPU 0 GPU 0 relative stress level\\t4021\",\n\t\t\t\t\t\t\t\t\"status\" : \"Pass\"\n\t\t\t\t\t\t\t},\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"gpu_id\" : \"1\",\n\t\t\t\t\t\t\t\t\"info\" : \"GPU 1 GPU 1 relative stress level\\t4021\",\n\t\t\t\t\t\t\t\t\"status\" : \"Pass\"\n\t\t\t\t\t\t\t},\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"gpu_id\" : \"2\",\n\t\t\t\t\t\t\t\t\"info\" : \"GPU 2 GPU 2 relative stress level\\t4022\",\n\t\t\t\t\t\t\t\t\"status\" : \"Pass\"\n\t\t\t\t\t\t\t},\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"gpu_id\" : \"3\",\n\t\t\t\t\t\t\t\t\"info\" : \"GPU 3 GPU 3 relative stress level\\t4027\",\n\t\t\t\t\t\t\t\t\"status\" : \"Pass\"\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t]\n\t\t\t\t\t},\n\t\t\t\t\t{\n\t\t\t\t\t\t\"name\" : \"Targeted Power\",\n\t\t\t\t\t\t\"results\" : \n\t\t\t\t\t\t[\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"gpu_id\" : \"0\",\n\t\t\t\t\t\t\t\t\"info\" : \"GPU 0 GPU 0 max power: 291.5 W average power usage: 288.6 W\",\n\t\t\t\t\t\t\t\t\"status\" : \"Pass\"\n\t\t\t\t\t\t\t},\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"gpu_id\" : \"1\",\n\t\t\t\t\t\t\t\t\"info\" : \"GPU 1 GPU 1 max power: 299.5 W average power usage: 297.1 W\",\n\t\t\t\t\t\t\t\t\"status\" : \"Pass\"\n\t\t\t\t\t\t\t},\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"gpu_id\" : \"2\",\n\t\t\t\t\t\t\t\t\"info\" : \"GPU 2 GPU 2 max power: 299.7 W average power usage: 296.7 W\",\n\t\t\t\t\t\t\t\t\"status\" : \"Pass\"\n\t\t\t\t\t\t\t},\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"gpu_id\" : \"3\",\n\t\t\t\t\t\t\t\t\"info\" : \"GPU 3 GPU 3 max power: 299.7 W average power usage: 299.0 W\",\n\t\t\t\t\t\t\t\t\"status\" : \"Pass\"\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t]\n\t\t\t\t\t},\n\t\t\t\t\t{\n\t\t\t\t\t\t\"name\" : \"Memory Bandwidth\",\n\t\t\t\t\t\t\"results\" : \n\t\t\t\t\t\t[\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"gpu_id\" : \"0\",\n\t\t\t\t\t\t\t\t\"status\" : \"Pass\"\n\t\t\t\t\t\t\t},\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"gpu_id\" : \"1\",\n\t\t\t\t\t\t\t\t\"status\" : \"Pass\"\n\t\t\t\t\t\t\t},\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"gpu_id\" : \"2\",\n\t\t\t\t\t\t\t\t\"status\" : \"Pass\"\n\t\t\t\t\t\t\t},\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"gpu_id\" : \"3\",\n\t\t\t\t\t\t\t\t\"status\" : \"Pass\"\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t]\n\t\t\t\t\t},\n\t\t\t\t\t{\n\t\t\t\t\t\t\"name\" : \"Memtest\",\n\t\t\t\t\t\t\"results\" : \n\t\t\t\t\t\t[\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"gpu_id\" : \"0\",\n\t\t\t\t\t\t\t\t\"status\" : \"Pass\"\n\t\t\t\t\t\t\t},\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"gpu_id\" : \"1\",\n\t\t\t\t\t\t\t\t\"status\" : \"Pass\"\n\t\t\t\t\t\t\t},\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"gpu_id\" : \"2\",\n\t\t\t\t\t\t\t\t\"status\" : \"Pass\"\n\t\t\t\t\t\t\t},\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\t\"gpu_id\" : \"3\",\n\t\t\t\t\t\t\t\t\"status\" : \"Pass\"\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t]\n\t\t\t\t\t}\n\t\t\t\t]\n\t\t\t}\n\t\t]\n\t},\n\t\"Driver Version Detected\" : \"550.127.05\",\n\t\"GPU Device IDs\" : \n\t[\n\t\t\"2237\",\n\t\t\"2237\",\n\t\t\"2237\",\n\t\t\"2237\"\n\t],\n\t\"GPU Device Serials\" : \n\t{\n\t\t\"0\" : \"1322922024488\",\n\t\t\"1\" : \"1322922074172\",\n\t\t\"2\" : \"1322922010286\",\n\t\t\"3\" : \"1322922063338\"\n\t},\n\t\"version\" : \"3.3.9\"\n}\n"}
{"level":"info","ts":"2025-01-02T09:15:53Z","msg":"DCGM diagnostic health summary: dcgmCheckLevel: 0 dcgmVersion: 3.3.9 gpuDriverVersion: 550.127.05, gpuDeviceIds: [2237 2237 2237 2237] replacementRequired: false rebootRequired:false"}
{"level":"error","ts":"2025-01-02T09:15:58Z","msg":"error publishing metric to cloudwatch: operation error CloudWatch: PutMetricData, get identity: get credentials: failed to refresh cached credentials, no EC2 IMDS role found, operation error ec2imds: GetMetadata, request canceled, context deadline exceeded"}
{"level":"info","ts":"2025-01-02T09:15:58Z","msg":"Logging Burnin Execution time metric","ExecutionTime":1,"_aws":{"Timestamp":1735809358639,"CloudWatchMetrics":[{"Namespace":"SagemakerBurninTest","Dimensions":[[]],"Metrics":[{"Name":"ExecutionTime","Unit":"Count"}]}]}}
{"level":"info","ts":"2025-01-02T09:15:58Z","msg":"Logging BurninExecutionCount metric","Burnin":"dcgm_nvidia","ExecutionCount":1,"_aws":{"Timestamp":1735809358640,"CloudWatchMetrics":[{"Namespace":"SagemakerBurninTest","Dimensions":[["Burnin"]],"Metrics":[{"Name":"ExecutionCount","Unit":"Count"}]}]}}
{"level":"error","ts":"2025-01-02T09:16:01Z","msg":"error publishing metric to cloudwatch: operation error CloudWatch: PutMetricData, get identity: get credentials: failed to refresh cached credentials, no EC2 IMDS role found, operation error ec2imds: GetMetadata, exceeded maximum number of attempts, 3, request send failed, Get \"http://169.254.169.254/latest/meta-data/iam/security-credentials/\": dial tcp 169.254.169.254:80: i/o timeout"}
{"level":"info","ts":"2025-01-02T09:16:01Z","msg":"Logging Burnin Execution time metric","ExecutionTime":1,"_aws":{"Timestamp":1735809361392,"CloudWatchMetrics":[{"Namespace":"SagemakerBurninTest","Dimensions":[[]],"Metrics":[{"Name":"ExecutionTime","Unit":"Count"}]}]}}
{"level":"info","ts":"2025-01-02T09:16:01Z","msg":"Logging Burnin Execution time metric","Burnin":"dcgm_nvidia","ExecutionTime":1750.251978602,"_aws":{"Timestamp":1735809361392,"CloudWatchMetrics":[{"Namespace":"SagemakerBurninTest","Dimensions":[["Burnin"]],"Metrics":[{"Name":"ExecutionTime","Unit":"Seconds"}]}]}}
{"level":"info","ts":"2025-01-02T09:16:57Z","msg":"Instance type: ml.g5.12xlarge, region: us-west-2"}
{"level":"info","ts":"2025-01-02T09:16:57Z","msg":"Test to be executed: efa"}
{"level":"info","ts":"2025-01-02T09:16:57Z","msg":"Executing efa loopback"}
{"level":"error","ts":"2025-01-02T09:16:57Z","msg":"Executing ib_send_bw for server with args [-x 0 -F --report_gbits -Q 1 -d rdmap0s26 -c SRD -n 1000 -p 18515 -a]"}
{"level":"info","ts":"2025-01-02T09:17:02Z","msg":"Executing ib_send_bw for client with args [-x 0 -F --report_gbits -Q 1 -d rdmap0s26 -c SRD -n 1000 -a 127.0.0.1 -p 18515]"}
{"level":"info","ts":"2025-01-02T09:17:05Z","msg":"Raw output for device: rdmap0s26, for operation: ib_send_bw :\n ---------------------------------------------------------------------------------------\n Send BW Test\n Dual-port : OFF\t\tDevice : rdmap0s26\n Number of qps : 1\t\tTransport type : Unknown\n Connection type : SRD\t\tUsing SRQ : OFF\n PCIe relax order: ON\t\tLock-free : OFF\n ibv_wr* API : ON\t\tUsing DDP : OFF\n TX depth : 128\n CQ Moderation : 1\n Mtu : 4096[B]\n Link type : IB\n GID index : 0\n Max inline data : 0[B]\n rdma_cm QPs\t : OFF\n Data ex. method : Ethernet\n---------------------------------------------------------------------------------------\n local address: LID 0000 QPN 0x0001 PSN 0xf232f6\n GID: 254:128:00:00:00:00:00:00:04:182:216:255:254:194:74:193\n remote address: LID 0000 QPN 000000 PSN 0x91583b\n GID: 254:128:00:00:00:00:00:00:04:182:216:255:254:194:74:193\n---------------------------------------------------------------------------------------\n #bytes #iterations BW peak[Gb/sec] BW average[Gb/sec] MsgRate[Mpps]\n 2 1000 0.021506 0.018417 1.151056\n 4 1000 0.043537 0.043340 1.354368\n 8 1000 0.087712 0.087223 1.362854\n 16 1000 0.17 0.17 \t\t 1.357973\n 32 1000 0.35 0.35 \t\t 1.359772\n 64 1000 0.70 0.69 \t\t 1.350833\n 128 1000 1.39 1.39 \t\t 1.355004\n 256 1000 2.76 2.74 \t\t 1.339825\n 512 1000 5.51 5.47 \t\t 1.335580\n 1024 1000 10.91 10.89 \t\t 1.329685\n 2048 1000 21.23 21.14 \t\t 1.290348\n 4096 1000 40.67 40.54 \t\t 1.237144\n 8192 1000 61.62 53.49 \t\t 0.816233\n---------------------------------------------------------------------------------------\n"}
{"level":"info","ts":"2025-01-02T09:17:05Z","msg":"EFA Loopback check passed for device: rdmap0s26 . Output summary is MaxBw: 61.620000, AvgBw: 53.490000, MaxTypicalLat: 0.000000, MinTypicalLat: 0.000000, AvgLat: 0.000000"}
{"level":"info","ts":"2025-01-02T09:17:05Z","msg":"Efa loopback check passed for all devices: [rdmap0s26]"}
{"level":"error","ts":"2025-01-02T09:17:10Z","msg":"error publishing metric to cloudwatch: operation error CloudWatch: PutMetricData, get identity: get credentials: failed to refresh cached credentials, no EC2 IMDS role found, operation error ec2imds: GetMetadata, request canceled, context deadline exceeded"}
{"level":"info","ts":"2025-01-02T09:17:10Z","msg":"Logging Burnin Execution time metric","ExecutionTime":1,"_aws":{"Timestamp":1735809430681,"CloudWatchMetrics":[{"Namespace":"SagemakerBurninTest","Dimensions":[[]],"Metrics":[{"Name":"ExecutionTime","Unit":"Count"}]}]}}
{"level":"info","ts":"2025-01-02T09:17:10Z","msg":"Logging BurninExecutionCount metric","Burnin":"efa_nvidia","ExecutionCount":1,"_aws":{"Timestamp":1735809430681,"CloudWatchMetrics":[{"Namespace":"SagemakerBurninTest","Dimensions":[["Burnin"]],"Metrics":[{"Name":"ExecutionCount","Unit":"Count"}]}]}}
{"level":"error","ts":"2025-01-02T09:17:13Z","msg":"error publishing metric to cloudwatch: operation error CloudWatch: PutMetricData, get identity: get credentials: failed to refresh cached credentials, no EC2 IMDS role found, operation error ec2imds: GetMetadata, exceeded maximum number of attempts, 3, request send failed, Get \"http://169.254.169.254/latest/meta-data/iam/security-credentials/\": dial tcp 169.254.169.254:80: i/o timeout"}
{"level":"info","ts":"2025-01-02T09:17:13Z","msg":"Logging Burnin Execution time metric","ExecutionTime":1,"_aws":{"Timestamp":1735809433433,"CloudWatchMetrics":[{"Namespace":"SagemakerBurninTest","Dimensions":[[]],"Metrics":[{"Name":"ExecutionTime","Unit":"Count"}]}]}}
{"level":"info","ts":"2025-01-02T09:17:13Z","msg":"Logging Burnin Execution time metric","Burnin":"efa_nvidia","ExecutionTime":7.9376522430000005,"_aws":{"Timestamp":1735809433433,"CloudWatchMetrics":[{"Namespace":"SagemakerBurninTest","Dimensions":[["Burnin"]],"Metrics":[{"Name":"ExecutionTime","Unit":"Seconds"}]}]}}
sh-4.2#
生成 AI に要約してもらいました。CloudWatch メトリクスの発行は失敗していましたがテストは通ったようです。(ドキュメントで言及されている部分を見つけられなかったため、非常に興味深いですね。)
メモリにもかなり負荷をかけたり、 GPU 性能の算出など、深いところまでテストされています。
1. インスタンスタイプ: ml.g5.12xlarge、リージョン: us-west-2
2. 3 つのテストを実行
1. hardware_check: ハードウェアのストレステストを実行し、成功
2. dcgm: NVIDIA GPU の診断テストを実行し、全てのテスト項目(デプロイメント、統合、ハードウェア、ストレス)をパス
3. efa: EFA ループバックテストを実行し、成功
3. GPU の状態
1. 4 基の GPU が搭載され、全て正常に動作
2. メモリ使用率は約 97.9 %
3. GPU 性能は約 759-765 gigaflop
4. 電力使用は各 GPU 約 290-300W
4. エラー
1. CloudWatch メトリクスの発行時に EC2 IMDS の認証エラーが発生(ただしテスト自体への影響なし)
Deep health checks の利用ケース
上記のように Deep health checks を使うとインスタンスが Ready になるまで時間がかかります。
ドキュメントにもノードが Ready になるまで約 2 時間の時間がかかること、バックアップ用リソース有無や待機できるかどうかで Deep health checks の使い分けが推奨されてます。
When the deep health checks are enabled, whenever a new instance is added to the HyperPod cluster (either during create-cluster or through automatic node replacement), the new instance goes through the deep health check process (instance level stress tests) for about a couple of hours. The following are suggested resilience config combinations depending on possible cases.
- Case: When you have additional spare nodes within a cluster as back-up resources (not using the full capacity), or if you can wait for about 2 hours for the deep health check process to get the less error-prone instances.
Recommendation: Enable the deep health check config throughout the cluster lifecycle. Node auto-recovery config is enabled by default.
- Case: When you don't have additional backup nodes (capacity is fully used for some training load). You want to get the replacement nodes as soon as possible to resume the training job.
Recommendation: Enable the deep health check during cluster creation, then turn-off the deep health check config after the cluster is created. Node auto recovery config is enabled by default.
- Case: When you don't have additional backup nodes, and you don't want to wait for the ~2 hour deep health check process (small clusters).
Recommendation: disable the deep health check config throughout the cluster life cycle. Node auto recovery config is enabled by default.
If you want to resume the training job from a failure immediately, make sure that you have additional spare nodes as backup resources in the cluster.
まとめ
以上、「SageMaker HyperPod の Deep health checks を試してみる」でした。
お高めな GPU インスタンスを、万全な状態でクラスターに参加できる点が、非常に素晴らしいと思いました。 SageMaker HyperPod らしい機能ですね。
このブログがどなたかの参考になれば幸いです。
クラウド事業本部コンサルティング部のたかくに(@takakuni_)でした!










